Claude Opus 4.8: Anthropic's New Flagship Tops Benchmarks Across Coding, Reasoning, and Alignment
Anthropic released Claude Opus 4.8 today, replacing Opus 4.7 as the company's strongest model. The pricing stays the same as Opus 4.7, fast mode runs at 2.5x speed, and fast mode costs are now 3x cheaper than previous models. Alongside the model, Anthropic launched dynamic workflows in Claude Code, effort control in claude.ai, and reported a 61% reduction in token cost for Databricks' Genie agent.
Here is what the numbers actually show.
Benchmarks: Where Opus 4.8 Stands
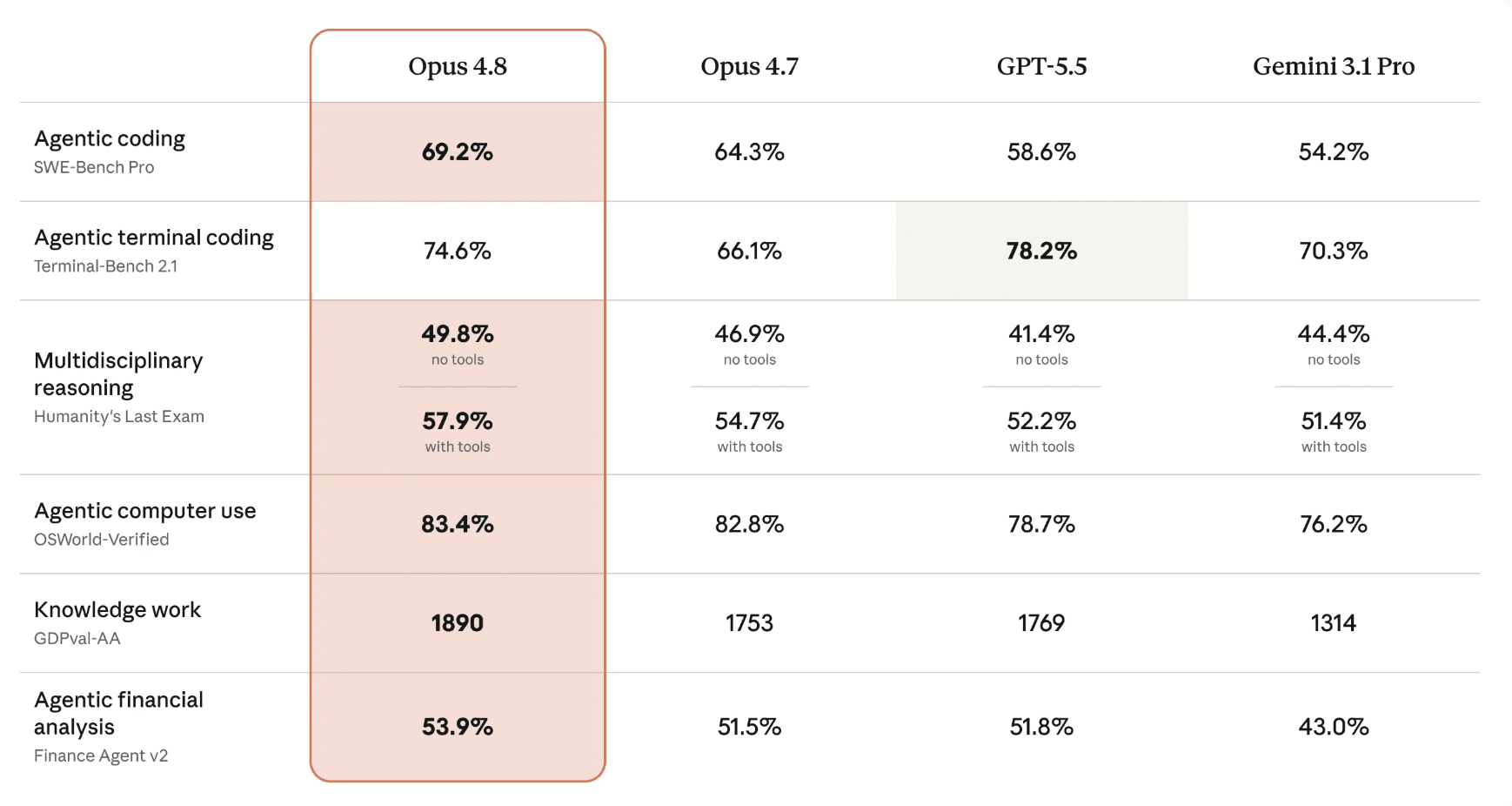
Opus 4.8 leads on most benchmarks against GPT-5.5 and Gemini 3.1 Pro. The gains over its predecessor Opus 4.7 are consistent and, in several cases, substantial.
On SWE-Bench Pro (agentic coding), Opus 4.8 scores 69.2%, up from 64.3% for Opus 4.7. GPT-5.5 sits at 58.6%, and Gemini 3.1 Pro at 54.2%. That is a 4.9 percentage point jump over the previous generation and a 10.6 point lead over GPT-5.5.
Terminal-Bench 2.1 (agentic terminal coding) is the one benchmark where GPT-5.5 leads at 78.2%. Opus 4.8 scores 74.6%, still a large improvement over Opus 4.7's 66.1%.
On Humanity's Last Exam (multidisciplinary reasoning without tools), Opus 4.8 reaches 49.8%, ahead of GPT-5.5 at 41.4% and Gemini 3.1 Pro at 44.4%. With tools enabled, the gap widens: Opus 4.8 at 57.9% versus GPT-5.5 at 52.2%.
For agentic computer use (OSWorld-Verified), Opus 4.8 scores 83.4%, beating all competitors. Its browser agent hits 84% on Online-Mind2Web, surpassing both Opus 4.7 and GPT-5.5.
Knowledge work (GDPval-AA) shows Opus 4.8 at 1890, compared to 1753 for Opus 4.7, 1769 for GPT-5.5, and 1314 for Gemini 3.1 Pro.
In financial analysis (Finance Agent v2), Opus 4.8 scores 53.9% against GPT-5.5's 51.8% and Opus 4.7's 51.5%.
On the legal side, Opus 4.8 is the first model to break 10% overall on the all-pass standard of the Legal Agent Benchmark.
If you want to compare token costs across these models for your own workloads, the LLM calculator at ComparEdge lets you run the numbers directly.
What Changed for Developers
The headline improvement for day-to-day coding: Opus 4.8 is approximately 4x less likely than Opus 4.7 to let code flaws pass unremarked. The model catches its own mistakes more consistently and pushes back on unsound plans.
Tom Pritchard, Staff Engineer at Shopify, described the difference: "Claude Opus 4.8 has noticeably better judgment. In Claude Code, it asks the right questions, catches its own mistakes, pushes back when a plan isn't sound, and builds up confidence around complex, multi-service explorations before making big changes. It's a great model to build with."
Devin, the agentic coding platform, reported that "Claude Opus 4.8 uses tools cleanly and follows instructions with the consistency our autonomous engineering workloads need to keep running unattended. It improves on Opus 4.6 and fixes the comment-verbosity and tool-calling issues we saw with Opus 4.7."
CursorBench confirmed that Opus 4.8 exceeds prior Opus models across every effort level, with more efficient tool calling.
Kay Zhu, Co-Founder and CTO, added: "On our Super-Agent benchmark, Claude Opus 4.8 is the only model to complete every case end-to-end, beating prior Opus models and GPT-5.5 at parity on cost. For agent products in translation, deep research, slide-building, and analysis, it delivers powerful reliability."
Alignment and Safety
Misaligned behavior (deception, cooperation with misuse) dropped substantially from Opus 4.7. Opus 4.8 scores near 1.83 on the misalignment metric, comparable to Mythos Preview, which Anthropic considers its best-aligned model. Opus 4.7 sat at 2.47 on the same scale. Lower is better.
Anthropic's alignment team stated that Opus 4.8 "reaches new highs on prosocial traits like supporting user autonomy and acting in the user's best interest."
New Features Launching Today
Dynamic workflows are available as a research preview in Claude Code. The model plans work and runs hundreds of parallel subagents within a single session. This enables codebase-scale migrations across hundreds of thousands of lines of code, from kickoff to merge. Available for Enterprise, Team, and Max plans.
Effort control in claude.ai lets users choose how much effort Claude puts into a response, giving more control over speed and depth.
Databricks reported that the Genie agent running on Opus 4.8 achieves a step change in agentic reasoning while cutting token costs by 61% compared to Opus 4.7.
Pricing
Opus 4.8 costs the same as Opus 4.7. Fast mode runs at 2.5x speed and is 3x cheaper than fast mode on previous models. For teams running large agent workloads, the combination of improved accuracy, lower misalignment, and reduced token costs makes this a straightforward upgrade.